The following page may contain information related to upcoming products, features and functionality. It is important to note that the information presented is for informational purposes only, so please do not rely on the information for purchasing or planning purposes. Just like with all projects, the items mentioned on the page are subject to change or delay, and the development, release, and timing of any products, features or functionality remain at the sole discretion of GitLab Inc.
Enable and empower data science workloads on GitLab
GitLab ModelOps aims empower GitLab customers to build and integrate data science workloads within GitLab. This stage also supports our FY24 Product Theme: GitLab for Data Science and the GitLab company vision of developing an AllOps platform.
Our ModelOps stage aims to accomplish the following:
The ModelOps Stage is currently outside of the GitLab DevOps lifecycle. We believe that data science features can span across all DevOps stages, making existing features more intelligent and automated.
Watch VP of Product David DeSanto, Engineering Manager Monmayuri Ray, and Principal Product Manager Taylor McCaslin discuss an overview of the GitLab ModelOps stage. They discuss the three pillars of ModelOps, including how to integrate Data Science into DevOps. This includes a brief history on how we got here, as well as where we are going. It discusses GitLab’s recent acquisition of UnReview and how GitLab plans to leverage ML/AI within our platform to improve user experience, as well as empower users to include ML/AI within their applications.
One of our primary goals for our ModelOps stage is to reduce the complexities of data science workloads and integrate these workloads to easily be managed and developed within GitLab.
Data scientists do not have the experience of DevOps engineers (and vice-versa). Their skills are not focused on building robust and production-ready systems. Much of data science work is experimentation, cobbling together whatever is needed to identify and produce value. Throughout this experimentation, lots of data, packages, tools, and code get written on a data scientist's machine. This creates a bespoke environment that is hard to reproduce, adds friction to handoffs, and diverges from production systems.

We want to help data scientists create repeatable environments with source code management and CI/CD at the heart of them. It should be easy for anyone on the team to explore the latest model experiment and iterate on it.
Because of the challenges with complex toolchains and lack of repeatable environments, handoffs can be a challenge with data science teams. These teams may produce amazingly valuable models and insights for an organization but when it comes time to deploy those models to production, it can take months. We want to help different teams across the software development lifecycle (SDLC) to better collaborate and handoff data, code, and models. We want to do that with the toolchain software engineering teams are already using.
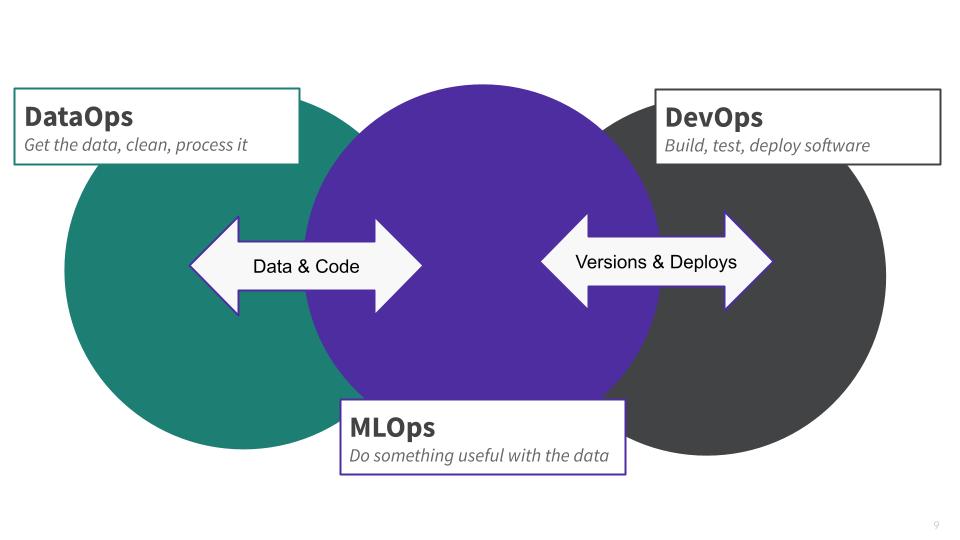
All together, these challenges lead data science teams to use specialized tools that don't integrate with each other or the existing software development lifecycle tools organizations already use. It leads teams to work in silos creating handoff friction and finger-pointing as well as guesswork and lack of predictability. Applications end up not leveraging data well and models take months to get into production and security is an afterthought. This creates risk for organizations, slows innovation, increases complexity, and increases the time to value. All of this could be avoided with an integrated DevOps platform that natively supports data science workloads. That's exactly what we are building.
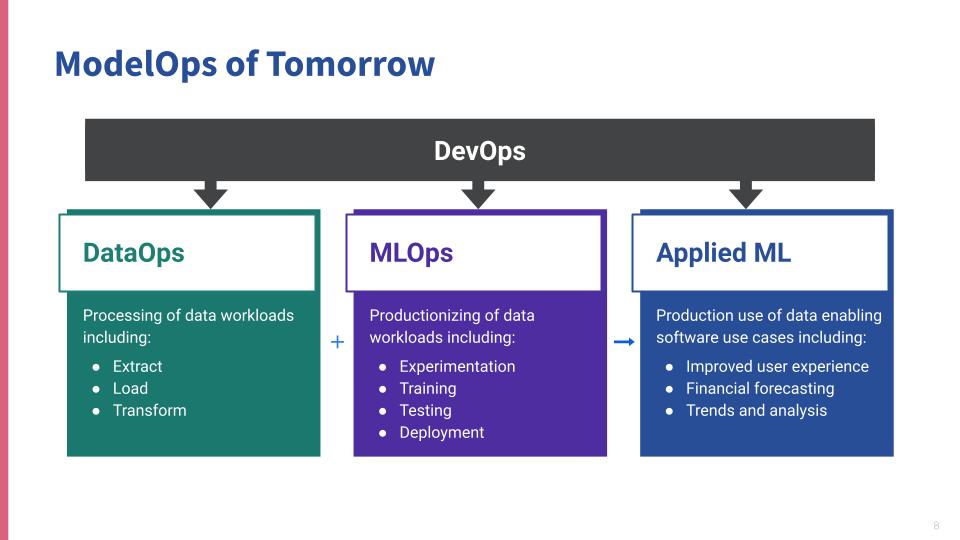
We are taking best practices from DevOps and applying them to data science workloads: From the processing of data workloads with Dataops to the productionization of data science models. Teams streamline handoffs because they are working in the same platform based on source code management with CI/CD and integrated security testing. Organizations can reduce risks associated with ML/AI, speed up innovation, reduce complexity, and reduce time to value.
There are two areas of relevance to GitLab ModelOps which we believe are critical to having end to end functioning data science workloads on GitLab:
GitLab ModelOps is currently composed of two groups. Data Science use cases are one of the four product investment themes for 2023 which align with GitLab's vision of fully integrating ModelOps within our DevOps platform.
These groups will be expanding with more roles opening throughout 2023:
2022 the ModelOps stage was actively staffing up and laying a foundation to build ML/AI powered features into GitLab. We established our ModelOps teams, introduced a new language to the GitLab stack (Python), and developed engineering processes to effectively enable GitLab to pursue the wider Data Science vision.
In 2023, we'll continue to grow teams in our ModelOps stage, expanding the use cases and features we are developing into the GitLab platform.
Internal team members can watch/read our latest updates from our latest ModelOps Group Conversation from October ( slides, video )
We've established a ModelOps internal handbook PI page (internal link) which will be updated monthly as part of PI review meetings. We're still working to actively orchestrate all our performance indicator metrics.
The ModelOps team is actively working to integrate machine learning into GitLab and the following outlines where we are currently investing our efforts:
The following will NOT be a focus over the next 12 months:
Last Reviewed: 2023-08-17
Last Updated: 2023-08-17